Mit der Ankündigung von VMware das in Zukunft keine SD Karten mehr als Boot/OS Speichermedium erlaubt sind war zumindest in
Weiterlesen
Citrix, VMware, Cloud und Co
Mit der Ankündigung von VMware das in Zukunft keine SD Karten mehr als Boot/OS Speichermedium erlaubt sind war zumindest in
Weiterlesen
Ich hatte neulich ein PoC bei einem größeren Kunden wo wir einen Citrix ADC(HA) in einer DMZ bereitgestellt haben um
Weiterlesen
Neulich hatte ich eine kleine Nuss zu knacken. Ich sollte für einen Kunden einen weiteren Terminalserver ausrollen. Der Kunde hatte
Weiterlesen
Mir ist es jetzt schon das zweite Mal passiert das ich bei einem Kunden FSlogix implementiert habe und nach der
Weiterlesen
Einleitung Ich bin schon viele Jahre als Trainer bzw. Dozent tätig. Anfänglich an der Volkshochschule danach bei meinen Arbeitgeber. In
Weiterlesen
In Part 1 meiner Citrix Cloud Serie habe ich über die Einrichtung der Citrix Cloud Connectoren gesprochen. In Part 2
Weiterlesen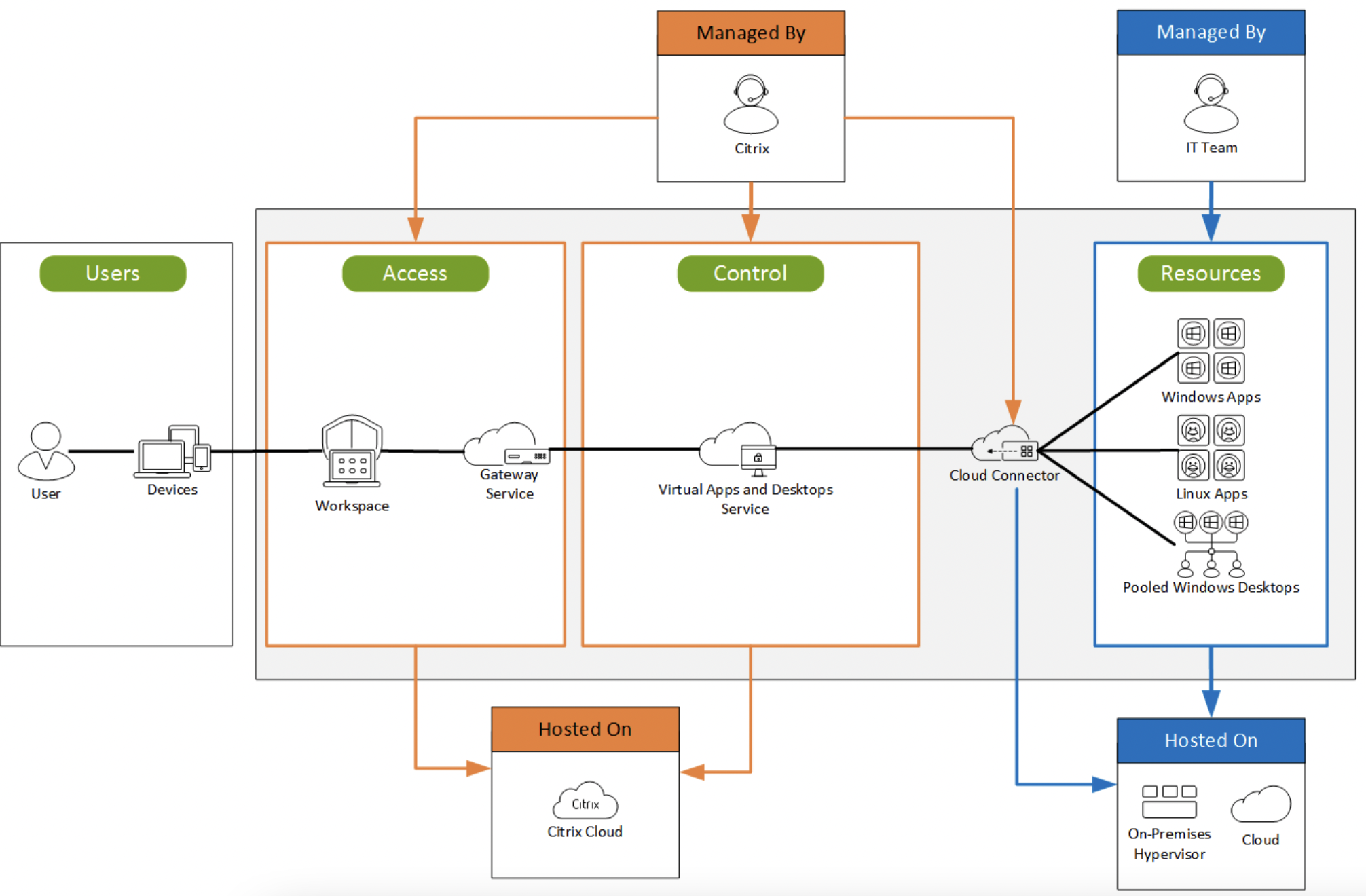
Ich versuche mich jetzt mal an einer Serie von Beiträgen zum Thema Citrix Cloud. Ziel ist die Bereitstellung einer Virtual
Weiterlesen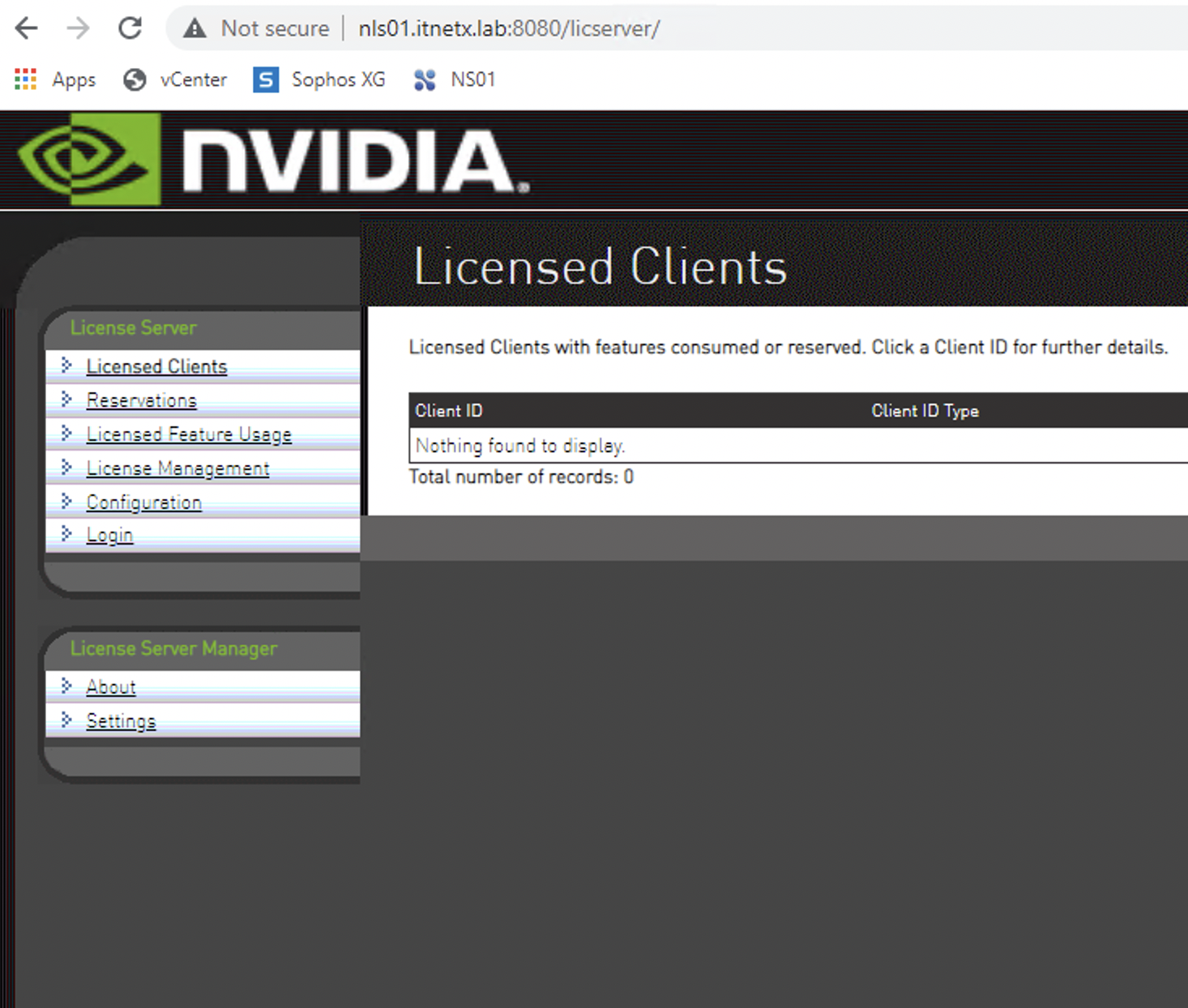
In den meisten POCs im Bereich Nvidia GRID habe ich den Lizenzserver auf irgendeinen bestehenden Windows Server mitinstalliert. Oft habe
Weiterlesen
Danke an Julian Jakob (@jakob_davidson) und sein Hinweis das die hier vorgestellte Lösung leider nur mit dem Browser funktioniert. Mit
Weiterlesen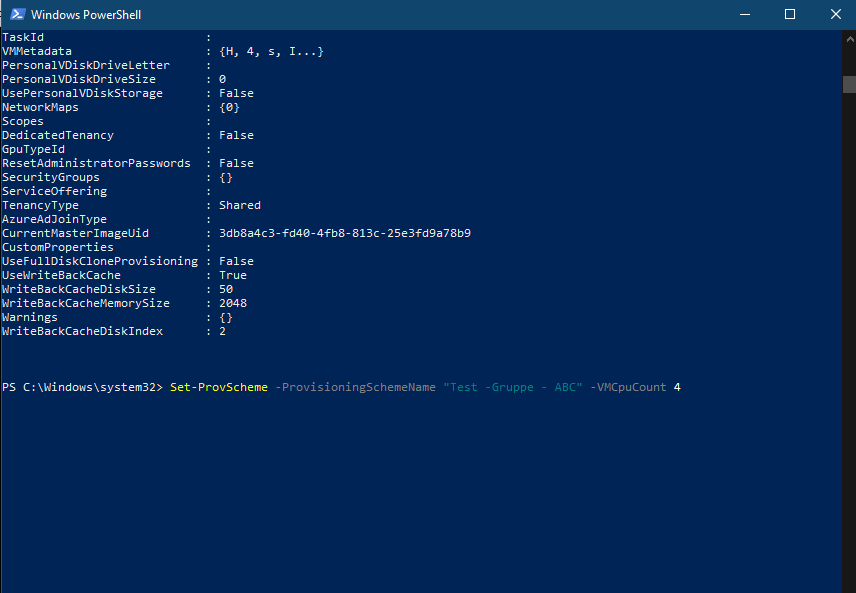
Mir ist es jetzt schon mehr wie einmal passiert das ich beim erstellen eines neuen Master Images meine VM nur
Weiterlesen